Where is the fashionable "end-to-end" intelligent driving?
From last year to this year, several new domestic forces and suppliers (Huawei, Yuanrong, Momenta, etc.) have called for "end-to-end" smart driving, and made it the focus of work in the second half of 2024. Whether "end-to-end" is the first initiative of Tesla is controversial, but there is no doubt that Tesla is the first enterprise to engineer and commercialize it.
If "full push" is the assessment point, in March 2024, Tesla pushed the official version of FSD V12 in North America. But after landing in China, we are still in the process. This gives many domestic enterprises the opportunity to say that they are as good as or even better than Tesla’s smart driving model in China.
On July 30th, Tucki promoted the XOS 5.2.0 version of AI Tianqi system to the whole world.
On September 11th, Huawei HarmonyOS Zhixing pushed ADS3.0. Interestingly, no matter which world, it has played down "Huawei" when talking about "end-to-end";
On October 23rd, Ideality launched "End-to-End +VLM", claiming to be the first in the industry. Ideal is indeed the first brand to actually combine the two;
Weilai is a little behind, and the high-profile "world model" has not yet landed-a Demo version with individual functions was launched in July.
A simulation of human brain decision-making
Since "End-to-End" is so fashionable, what is "end-to-end"? Sorry, there is no recognized accurate definition. Just like the end-to-end mechanism, it is basically a self-pulled and self-singing program.
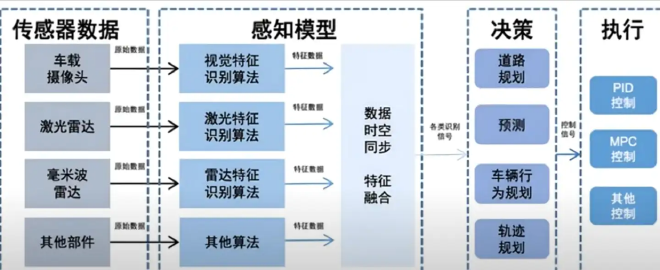
Explanation of low EQ-"End-to-end" is a technical route to realize intelligent driving. Smart driving from CNN, RNN, GAN, to Transformer model (typical application is NOA of urban light map), until today’s end to end. "End-to-end" refers to the integration of classical perception, planning, decision-making and execution, and the decision-making and execution are directly generated by perception.
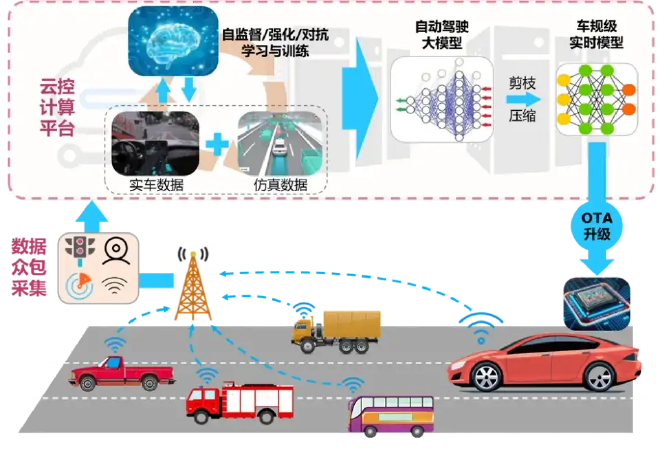
When you see the word "generate", it is easy to understand that this is the same way as ChatGPT, that is, to build a model with numerous parameters (possibly more than 100B, 1b = 1 billion), and train this model with data through powerful computing power, expecting it to produce wise decisions, regardless of whether it has encountered the next new scene. In this way, end-to-end is actually to solve the long tail (rare scene) problem of intelligent driving by means of a large model.
High emotional intelligence explanation-don’t understand the above a lot of abbreviations? Nothing! For example, you are possessed by cattle and horses, and you keep calling to handle official business on the way to work, and you drive home unconsciously, and you can’t remember how to get home later. The driving behavior of this road is end to end.
To put it bluntly, it is trying to simulate the decision-making mode of the human brain with a large model and deal with endless new scenes wisely.
Some people think that this explanation is the same as not saying it. In fact, it makes sense to think so. It is very similar to the task of "pushing the elephant into the refrigerator". It is very clear to open and close the door (because it conforms to people’s life experience), but the key steps to push the elephant in are not clear.
I don’t blame the technicians, because I really can’t say it clearly. Their explanation is "poor interpretability", isn’t it irritating?
But don’t worry, for users, the end-to-end admiration and voice, from a narrow group (enthusiasts and smart enthusiasts) to the whole people, are increasingly becoming the excitement of the whole people. End-to-end full-volume push, users who are highly concerned about domestic brands are no less discussed than investors, and they are expecting a counterattack in some sense (although the amount of information they obtain or understand is uneven).
At present, human technology, perception is no problem, and decision-making to implementation is no problem. How to go from perception to decision-making is a big problem. People don’t really know how the human brain thinks. But the principle is "experience determines prediction", which is where human driving is better than AI at present. This is the truth that a person with poor mathematical logic, even a person without much culture, can drive a good car. End-to-end saves the regulation and control, makes direct decision, and speeds up the feedback. Enterprises hope that the accuracy of decision-making will not decrease but increase.
Conservatives and fundamentalists
It has been suggested that the end-to-end essence should be the lossless transmission of perceptual information, which is reasonable but difficult to understand. In fact, the essence of end-to-end is to consider how to think without rules This does not mean abandoning traffic rules, but without the need for programmers to prepare a response plan for every possible scenario in advance, AI will find the best answer based on the scene in front of it. Therefore, the end-to-end approximation can be described as a "prediction model based on experience and basic rules".
(Classical regulatory model)
The intelligent driving scheme before end-to-end is a combination of multiple modules. Perception, planning and control are independent. There are delays and data missing in the transmission of information in series modules, and the gradual accumulation of errors may also bring security risks.
Theoretically, end-to-end should integrate the three and eliminate the internal data interface. However, Tucki, Ji Yue and other "conservatives" still practice two-stage "end-to-end", that is, perception and regulation are divided into two models. Tucki’s former is called Xnet (Perceptual Neural Network), while the latter is called XPlanner and Visual Language Model (VLM)XBrain.
Fundamentalists, on the other hand, believe that "two-stage" has not broken away from the traditional pattern of intelligent driving, that is, the interface between the two networks is still artificially defined. The problems of information drift and delay in traditional intelligent driving have been inherited (although improved).
The advantage of the two-stage method is that since human beings have defined the intermediate interface, they can understand the intermediate result, which is convenient for checking the system and finding out the faults. For example, if something goes wrong, you don’t need to retrain the whole system with "good data". It is also easy to trap the lower limit of the system and avoid incredible mistakes.
However, like Tesla, the "4D One Model" ideally announced on October 23rd is a one-stage model, that is, end-to-end +VLM.
VLM seems essential, but it is also a big model. It is a multimodal model that can be learned from images (traffic scenes) and texts (traffic signs). In short, input images and text, and output (generate) text. This text is used to regulate the model to understand the meaning of the scene.
The difference between VLM and the end-to-end model itself is that it has generalization ability without training (of course, it can be trained better). Its most important task is to obtain the spatial attributes in the image, that is, to identify obstacles and motion paths.
Both VLM and end-to-end large model are black boxes. People don’t know how it generates cognition and decision-making, just like they don’t know how to push an elephant into a refrigerator, but it turns out to be pushed in.
This is the so-called "low interpretability". That is, the decision logic can be understood, but the process is not. Once the decision-making result goes wrong, there is no other way but to continuously increase the data feeding amount, adjust the model parameters, and pile up the model accuracy as much as possible, but it does not guarantee 100% safety.
It must be admitted that end-to-end has expanded the upper and lower limits of the intelligent driving system at the same time, which is why some enterprises have followed the trend and trained for a long time, and found that the performance of the system is worse. This is tangled, so it is necessary to "draw a red line", such as rules such as never running a red light, and make it clear in the neural network. This is the bottom principle.
The big model needs a "wet nurse"
Building and training large models requires a lot of money first. Because it is on the order of class B parameters, even storing data is very expensive.
At present, the computing power support of Tesla Supercomputing Center consists of D1 chip and supercomputer Dojo. With an investment of $1 billion, we finally managed to achieve 100EFLOPs(1EFLOPs is 1018 floating-point operations per second), and this deployment has not yet been completed.
The threshold of smart cloud computing power is roughly 1EFLOPs, and the current average background computing power of car companies is 3 EFLOPs. Huawei’s background computing power may be 7.5 EFLOPs. The computing power deployment plans of the three major telecom operators range from 15 to 21 EFLOPs.
(End-to-end process schematic)
The ideal training computing power (not equal to the final power) is 5.39 EFLOPs, which consists of 5,000 computing cards (NVIDIA A100 and A800), while A100, which is used to train the production model, is quoted at RMB 100,000, while A800 is at least RMB 120,000.
Obviously, the construction of the supercomputer center must be supported by large funds, and even the monthly electricity bill may be as high as several million yuan. In the automobile circle, the scale of computing power used by Tesla for training in the next few years is obviously the largest.
With hardware, there must be data. The amount of data determines the quality of training.
In July, Musk’s analogy at the earnings conference was widely known. He said that FSD V12 "trained 1 million video cases and barely worked; 2 million, slightly better; 3 million, you will feel, Wow;; 10 million, it will become incredible. " Of course, Lao Ma, as the godfather of communication, need not entangle the specific data, only knowing that the amount of data is positively related to the correctness of system decision.
It needs to be clear that "bad data" (green driving, bad driving habits, violation of traffic rules, etc.) will "drag down" the training effect of the big model. Simply put, it is best to be an old driver who is rational, law-abiding and restrained.
Tesla’s shadow driving can get a lot of data. The essence of training is imitation. Imitate it and you will become an apprentice. Then the question is coming. Who will guarantee the quality of the feeding data? Still have to manually review. Even if it is not purely artificial, it is necessary to do some screening under artificial rules. Just like no map (actually a light map), it is also necessary to make manual labeling.
Heap of human resources is also an expensive investment, and it is doomed that training will not be improved too soon. High quality data means rare scenes+good data. If the number of products can’t go up, it also means that there is not much good data, the training improvement will be slow, and the system iteration will lag behind the opponent.
Under the premise of similar ideas, investment and technology paths, product ownership has become the most important winning factor for the level of intellectual driving. Then, who has a large investment in computing power, a clear path and a larger absolute product quantity? The conclusion is coming out.

(Tesla FSD status)
If so, the end-to-end "wet nurse" is investment, data, manpower and patience!
The idea of end-to-end is born from the breakthrough of big model and computing power, and it is just a seemingly promising route. The problem now is that after training to a certain level, the system improvement may encounter bottlenecks (the amount of training is gradually decoupled from the effect). The enterprises that are ahead now may have encountered the "data wall", but they are all secretive. Nowadays, some people think that since the strength is great, the end-to-end model parameters reach 100B (about the same order of magnitude as ChatGPT4.0) and the training volume reaches 100 million, will there be a qualitative leap in the level of intelligent driving?
No one has tried this yet. Before generating enough economic returns, build such a system, and doubt that the purse will not hold up first. Musk’s "firstness" is a good thing, but it doesn’t mean that Teacher Ma himself is firstness.
From Transformer+BEV to end-to-end, the first echelon in China has been following Tesla’s thinking closely, half a year to one year behind, while the second echelon is behind Tesla for about two years, that is, it has just started to build the system. So far, it is not an exaggeration to say that Tesla is a smart driver. And Waymo’s Robotaxi did not have such a great influence. Now Tesla has also begun to advocate Robotaxi, and whether domestic car companies will continue to follow up is also a point of view. Generally speaking, everyone is making a fuss about sales. As for the grand narrative that affects and shapes human transportation and lifestyle, only the surviving enterprises are qualified to think about this issue.